

Reducing the Netezza Query Runtime on Very Large Tables
In this blog we'll show you how to massively reduce the runtime of Netezza queries on very large tables.
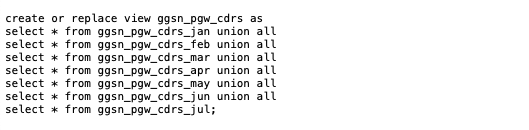
In this example, one of our Virtual DBA customers, a Telco, was asking for advice on how to improve the runtime on various queries against large tables containing call detail records (CDR's). In this example we partitioned one of these tables containing 7 months of data into monthly partitions and created a UNION ALL view over them.
$ cat cdrs_vw.sql
$ nzsql -d TESTDB -f cdrs_vw.sql

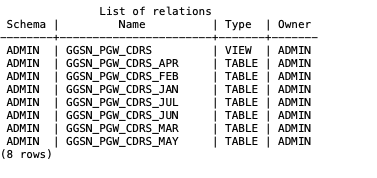
$ nzsql -d TESTDB -c "\d"
$ nzsql -d ORIGDB -c "explain select count(*) from CDRS where rec_open_time BETWEEN To_timestamp('2021-01-30 00:00:00','YYYY-MM-DD HH:MI:SS') AND To_timestamp('2021-01-31 23:00:00','YYYY-MM-DD HH:MI:SS');"

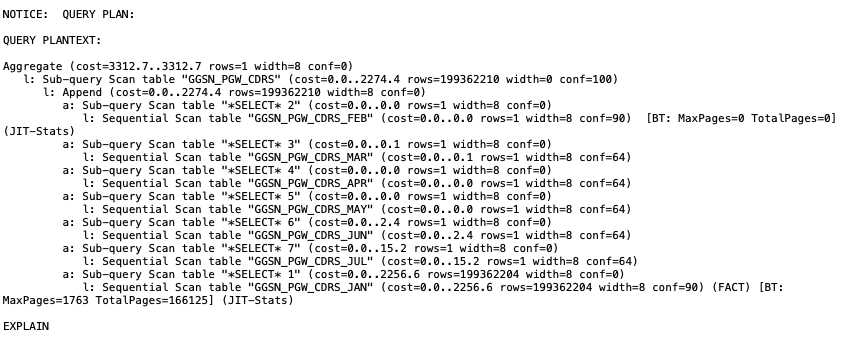
$ nzsql -d TESTDB -c "explain select count(*) from CDRS where rec_open_time BETWEEN To_timestamp('2021-01-30 00:00:00','YYYY-MM-DD HH:MI:SS') AND To_timestamp('2021-01-31 23:00:00','YYYY-MM-DD HH:MI:SS');"
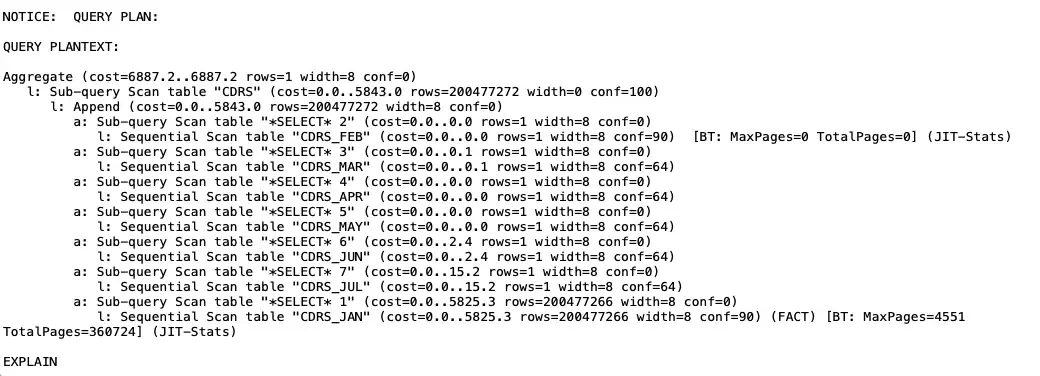
A typical user query (from pg.log) which filters records for a time period ran in 7.6s on the original table (6 billion rows on an idle system).
$ nzsql -d ORIGDB -c "select count(*) from CDRS where rec_open_time BETWEEN To_timestamp('2021-01-30 00:00:00','YYYY-MM-DD HH:MI:SS') AND To_timestamp('2021-01-31 23:00:00','YYYY-MM-DD HH:MI:SS');" -time

The same query ran in 1.3s on the view. The optimiser appears to have skipped over all the partitions that didn’t have the relevant data.
$ nzsql -d TESTDB -c "select count(*) from CDRS where rec_open_time BETWEEN To_timestamp('2021-01-30 00:00:00','YYYY-MM-DD HH:MI:SS') AND To_timestamp('2021-01-31 23:00:00','YYYY-MM-DD HH:MI:SS');" -time

$ nzsql -d TESTDB -c "alter table CDRS_JAN organize on (REC_OPEN_TIME)"

Next, because the partitions were now smaller manageable chunks, we ran a GROOM RECORDS ALL on one of the partitions to physically order the rows by the organization key.
$ nz_groom TESTDB CDRS_JAN -records all

Runtime was further reduced to 0.6s, which was an overall improvement of over 12 times.
$ nzsql -d TESTDB -c "explain select count(*) from CDRS where rec_open_time BETWEEN To_timestamp('2021-01-30 00:00:00','YYYY-MM-DD HH:MI:SS') AND To_timestamp('2021-01-31 23:00:00','YYYY-MM-DD HH:MI:SS');"
$ nzsql -d TESTDB -c "select count(*) from CDRS where rec_open_time BETWEEN To_timestamp('2021-01-30 00:00:00','YYYY-MM-DD HH:MI:SS') AND To_timestamp('2021-01-31 23:00:00','YYYY-MM-DD HH:MI:SS');" -time

Interestingly, by adding a new column to store the MSISDN value as INT8 rather than VARCHAR, zone maps kicked-in and the execution cost dropped a massive 85%, with a new runtime of 0.12s. That was an overall improvement of 60 times!
Obviously the runtimes will vary according to system load - these examples were achieved on an idle system - but the performance gains will be of a similar magnitude.
Try it yourselves, and if you have any questions feel free to contact us.