In our blog Netezza Performance Server De-Mystified we talked about how Netezza Performance Server for IBM Cloud Pak for Data had become a de-facto one stop shop for all things data, especially if you are an existing Netezza customer. In this blog we’ll take a broader look at IBM’s integrated cloud data platform that makes it easy to deploy, scale, manage and stitch together cloud databases with analytics and AI services across IBM Cloud and 3rd party public cloud vendors, underpinned by Red Hat OpenShift.
Here is an overview of the Integrated Cloud Data Platform that was recently presented by IBM at FastStart 2021.
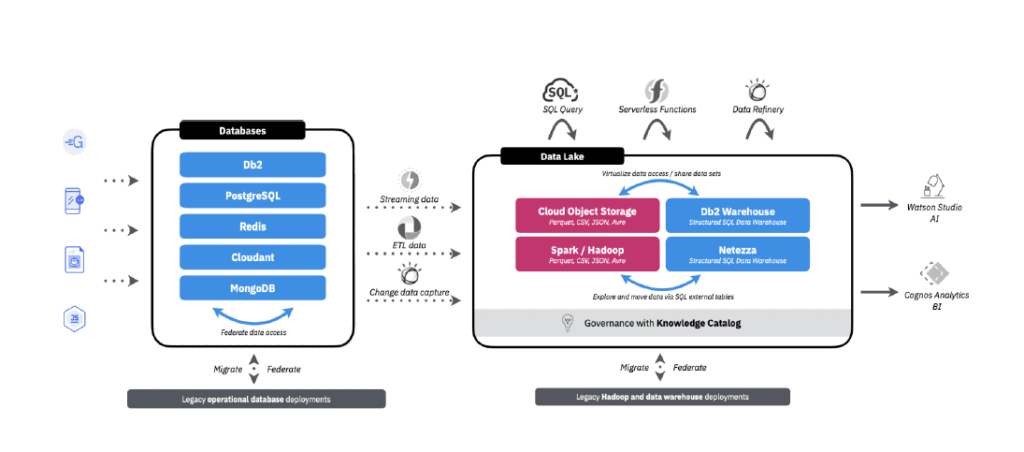
Here we see that IBM recognises that we live in an increasingly open-source, cloud-centric world where everybody is or will soon be doing Artificial Intelligence and Machine Learning. IBM’s traditional range of proprietary systems no longer cater for everybody’s requirements as they may once have, so in Cloud Pak for Data IBM supports a variety of SQL and NoSQL databases and a mix of IBM proprietary and open-source offerings. Accordingly, the message is that if customers are already using these things and are happy with the functionality provided by open-source alternatives to licensed product offerings, IBM can still be relevant to these customers.
Horses for Courses
Essentially, every requirement imaginable is covered by one or more of the databases now supported by IBM in its Cloud Pak for Data. The list above is not exhaustive – there are other niche database products niche database products available on the platform. Looking at the operational databases listed here though, on one hand you have DB2 which was the second relational database ever to be released commercially and as such some people in the database space may consider it to be a monolithic dinosaur. The relational database was invented in the 1970’s by IBM scientist Doctor Edgar Codd and DB2 was launched in 1983. So, there’s the perception that it is kind of old-hat and therefore not cool.

Nonetheless, DB2 has not stood still since it was developed. It has continuously been enhanced and improved and for enterprise use, it’s an invaluable product. It has features that many application developers don’t really appreciate or consider, such as reliability, data integrity, and enterprise-level security. These are the things that businesses need and depend on. It is a rock-solid online transaction processing database, first and foremost. You can bet your business that whenever somebody buys something from your store or your website that DB2 will record the transaction and that it’s not going to get lost. It’s impossible that a customer will buy a product and because of a system error will end up not paying for it. It is important also to acknowledge that DB2 is now more than a transactional database – it is now being positioned by IBM as The AI Database, so it has been enhanced with many machine learning and AI features.

DB2-like but open source is PostgreSQL, which is now extremely reliable, mature and very feature rich. A historical problem with open-source technologies is getting support when they break. Companies like Enterprise DB (which acquired 2nd Quadrant) have evolved to provide that enterprise support niche, supporting open-source products like PostgreSQL. Funded by customers to add functionality to Postgres, they have contributed to the codebase. The benefit to the customer is that they get the functionality first, and when it then gets incorporated into the open-source code base the entire community benefits.
A new generation of NoSQL databases
There are 3 NoSQL databases in the list. NoSQL, which stands for “not only SQL,” is an approach to database design that provides flexible schemas for the storage and retrieval of data beyond the traditional table structures found in relational databases. NoSQL databases have recently become very popular in the development of cloud, big data and high-volume web and mobile applications. They offer better scalability, performance and ease of use than relational databases. The most common types of NoSQL databases are key-value, document, column and graph databases.

Redis is an open-source in-memory NoSQL database, favoured for the speed that comes from having everything in memory, and being able to minimise the number of calls your application makes to the cloud, which is important given the high cost of cloud computing. There are modules for all the common NoSQL database types, so it is extremely versatile.
Cloudant and MongoDB are primarily NoSQL document databases. Cloudant is a distributed database-as-a-service (DBaaS) that is based on Apache CouchDB, whereas MongoDB is the open-source market leader and is available in a variety of paid and free services, in the cloud or on premises. In document databases, the data is stored and queried as JSON-like documents that don’t need to be pre-defined in the database. Fields can vary from document to document and the structure can be modified at any time. Document databases enable flexible indexing, powerful ad-hoc queries, and analytics over collections of documents. Typical use cases are blogs and video platforms, and e-commerce catalogs where product attributes continually change.
The popularity of document databases stems from the fact that that the kinds of things people are storing nowadays in databases don’t fit the relational database model. People are using languages such as Java, Ruby or Python with rich data structures. Mapping a complex structure in one of these programming languages back to a relational data model is complicated. In Mongo and Cloudant, however, you can store complex structures in a single document, so productivity is dramatically improved. Moreover, this technology lends itself to distributed systems where horizontal scalability is key.
Co-locating your data with your analytical systems
It’s when you look at the right side of the diagram that you can see how powerful a unified cloud platform is. By co-locating all of its database and analytical systems in Cloud Pak for Data your data resides in the same physical location as your AI and machine learning software. In the past you would normally have to move a subset of data from your data storage to where the machine learning software lives, whether that’s SAS, R or whatever. This means that you were typically not able to do the machine learning training and scoring on large quantities of data – in fact, most traditional machine learning approaches only use a really small sample of data. Netezza’s and DB2’s in-database machine learning ability means you don’t have to take a copy of the database and move it anywhere. By using data virtualization, you literally have access to your entire data lake, however it is stored, plus any other operational databases you are running in parallel. Whether you would use DB2 or Netezza depends on a number of factors. There are hard core loyalists of both products, but over time DB2 has been enhanced with features that were previously only available on Netezza, and Cloud Pak for Data was originally designed for DB2. It was later that Netezza was added back to the IBM product suite when its absence was sorely felt. There is a strong argument for Netezza having the speed advantage over DB2 because of its superior parallel processing of workload, but whether to use one over the other if you are not an existing user of either is probably best discussed in another blog.
Customer choice is key
Another key message that IBM is sending with its unified data platform is that it does not need to be a binary decision whether to deploy everything to the cloud. Certainly cloud storage is incredibly cheap and it just makes financial sense to locate your data lake in the cloud. Furthermore, if all of your data is in the cloud, that’s where your databases need to be as well because moving data up to the cloud and then moving it back again is really slow and relatively expensive to do. This is why we have the explosion in popularity of products like Snowflake, Redshift, Google Big Query and Big Table, and Azure Synapse, which are not represented in this diagram. But most of these are proprietary. RedShift, for example, is proprietary to Amazon, you can’t get it anywhere but AWS. Similarly Azure Synapse only works on the Azure platform. Snowflake have been very clever in that they have made the product cloud neutral and so if you want to run Snowflake on any cloud, you can. IBM’s strategy is to give customers choice by not saying that everything has to be on-premise or in the cloud or even IBM.

There will always be things that happen on premise such as price checking in a supermarket where you wouldn’t want to rely on a broadband connection to be able to calculate the correct price. If every chain store in the world was reliant on the internet to work and it were to go down for whatever reason, the AWS service they were using for example, then commerce would stop and that is too disruptive.
With Cloud Pak for Data you can have DB2 on premise and DB2 in the cloud at the exact same time, and by the way if you want to have it on Azure or AWS, or Google, you can. IBM’s own cloud service is good, but IBM does not insist that you only use their service as do Amazon, Google and Microsoft.
A good starting point for Artificial Intelligence
Cloud Pak for Data provides an IDE (Interactive Development Environment). It comes with Watson Data Studio, which provides a really convenient front-end environment for those type of AI /ML workloads and is a good starting point for customers who are new to AI/ML. It also comes with Jupyter Notebooks which makes it very easy to document your process and share it without having to write any software, so you don’t have to buy a query tool or have to build an entire application by yourself in-house. All of these components are included on the base nodes of Cloud Pak for Data System – you are not using these powerful tools you should think about exploiting these capabilities.
In summary, with Red Hat OpenShift and Cloud Pak for Data IBM has changed course quite considerably. It has moved away from giving companies a binary choice – IBM or not IBM – and is now providing a platform that consists of an integrated set of services for building analytics and machine learning models. Furthermore, and unusually among hybrid cloud offerings, Cloud Pak for Data also has a third-party ecosystem of supported services. This really does reflect IBM’s new-found mantra of giving its customers choice.
Interested in finding out more? Give us a shout.


