In our blog An Easy Migration – Is There Such a Thing? we looked at a number of things that should be considered when refreshing your data warehouse technology. In this blog we’ll explore the nuts and bolts of the actual data migration and how you can and should consider data migration tools to do the heavy lifting for you.
How hard your data migration will be depends on a number of factors, such as:
- Data complexity
- Data volumes
- Compatibility of target system
Data Complexity
The growing trend towards mobile data, cloud-computing and the adoption of advanced technologies such as the Internet of Things (IoT) and Artificial Intelligence (AI) means that companies are collecting a lot more data of increasing complexity. Datasets may include binary large objects (blobs) such as images, audio tracks, video clips and other complex data and non-Latin character sets such as Japanese and Chinese, to name but a few. This means that migrating from one platform to another is a completely different ballgame than it used to be.
Data Volumes
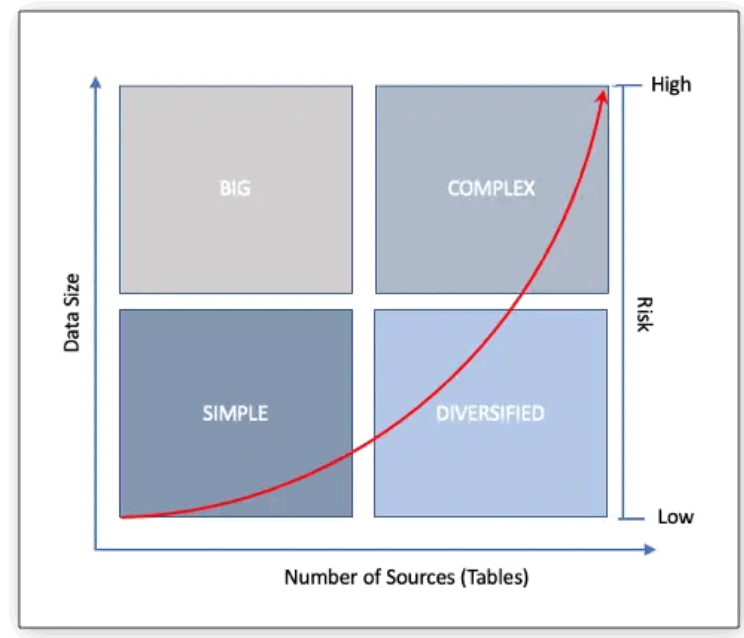
Complex data would not pose a problem if they were spread over only a handful of tables, but now that data is being measured in gigabytes, terabytes and even petabytes, being able to handle data transformations at scale is no small task. In the chart you’ll see how increasing volumes combined with increased number of data sources and tables drastically increases the risks associated with a data migration.
Compatibility of target system

Given that every database system has its own peculiarities, there are a number of steps that must be taken to ensure that when the data is migrated, it retains 100% of its integrity and has not been truncated or misinterpreted in any way. So, this means understanding the translations that must occur on the data, the ability to do these translations automatically, and most importantly to be able to validate the data in its new environment. Not planning for all the differences between both systems is like executing your data migration as a game of snakes and ladders – the tools you use will help you take big steps forward, but at any time during the process you may encounter problems that set you way back. To succeed, you have to be able to predict the throw of the dice and avoid the backward steps, otherwise you will be continually going around the board and feel like you’ll never reach the end point.
Introducing Smart Data Frameworks
If you have come to the conclusion that you shouldn’t be relying on scripts, error logs and end user reports to determine whether your data has arrived safely and accurately in your new target database, read on. Smart Data Frameworks has been designed to handle the triple constraint of data complexity, data volumes and target system compatibility and to do all the heavy lifting for you. There are a few such tools in the marketplace, and right now we’d like to share with you how we do things differently.
The Secret is in the Data Validation
Being able to validate the target data matches the source data is often skirted over but in fact it is the most important stage in the data migration. There is a common belief that if the data can be exported from the source system and loaded into the target system and the load doesn’t fail, it must be ok. That is a dangerous assumption to make.
Ordinarily, to validate the data you do table level hash checks. You run a function on a whole table and produce a number, and if you produce the same number on the target table you know they are identical. Conversely, if the numbers are different there is a discrepancy. Doing hash level comparisons can tell you things are matching or different, but what they don’t tell you is where or why they are different, and that is crucially where SDF differs from the others. By comparing every single column and every single row it means that any discrepancies that are identified are traceable and auditable down to that granular level.
Some people may think “how hard can that be?” and the answer is actually surprisingly difficult because of the fact there are differences in the way internal data might be stored on your source and target technologies. Moreover, because of the way hash functions work we need to guarantee that we are comparing apples with apples.
If you want, for example, to compare a date type without converting it first to a standard date format then it would think that 01012020 is different from 2020-01-01. So we first translate the date into the same format as the target table, and then run the hash function on the table. This is a very simple example but imagine far more complex examples in millions of rows of thousands of tables and then ask yourself again “how hard can that be?”
Hash Comparisons
For each table, SDF computes a hash value for every primary key on the source and target which enables us to then see on a row by row basis if they are identical or different. If different, because we have the primary key, we can go back to the original row and look at the individual attributes and the row level on the source and target system to see why the hash values don’t match and what the difference is from column to column. Doing all this reconciliation by hand would be prohibitively time consuming and expensive, so being able to automatically do it in a robust fashion is a big point of difference.
Some customers may want to have a rolling rather than a big-bang migration whereby they parallel run on both source and target systems side by side for a period of time and then they cut over when they are confident that their source and target systems correspond and their target system, is fit for purpose.
This is another thing that SDF supports, we can migrate only the data that has changed since the last migration, so that we can continuously keep the target environment in sync with the source environment. We can also restrict the validation process so that only data that has changed gets validated, assuming all the previous data that has already been validated and passed successfully. What that means is that we can do a miniature migration every day – continuously and indefinitely until the customer is ready to cut over. Doing all that manually would effectively require the same effort as doing a full migration on a continuous ongoing basis, whereas our process is entirely repeatable, and all the code is automatically generated.
If you have a complex data set to migrate and would like to have a look at how Smart Data Frameworks can do the heavy lifting for you, why not contact us for a free demo right now. More insights here.


